LISP vs EVPN: Mobility in Campus Networks
I decided not to get involved in the EVPN-versus-LISP debates anymore; I’d written everything I had to say about LISP. However, I still get annoyed when experienced networking engineers fall for marketing gimmicks disguised as technical arguments. Here’s a recent one:

TL&DR: The discussion on whether “LISP scales better than EVPN” became irrelevant when the bus between the switch CPU and the adjacent ASIC became the bottleneck. Modern switches can process more prefixes than they can install in the ASIC forwarding tables (or we wouldn’t be using prefix-independent convergence).
Now, let’s focus on the dynamics of campus mobility. There’s almost no endpoint mobility if a campus network uses wired infrastructure. If a campus is primarily wireless, we have two options:
- The wireless access points use tunnels to a wireless controller (or an aggregation switch), and all the end-user traffic enters the network through that point. The rest of the campus network does not observe any endpoint mobility.
- The wireless access points send user traffic straight into the campus network, and the endpoints (end user IP/MAC addresses) move as the users roam across access points.
Therefore, the argument seems to be that LISP is better than EVPN at handling a high churn rate. Let’s see how much churn BGP (the protocol used by EVPN) can handle using data from a large-scale experiment called The Internet. According to Geoff Huston’s statistics (relevant graph), we’ve experienced up to 400.000 daily updates in 2021, with the smoothed long-term average being above 250.000. That’s around four updates per second on average. I have no corresponding graph from an extensive campus network (but I would love to see one), but as we usually don’t see users running around the campus, the roaming rate might not be much higher.
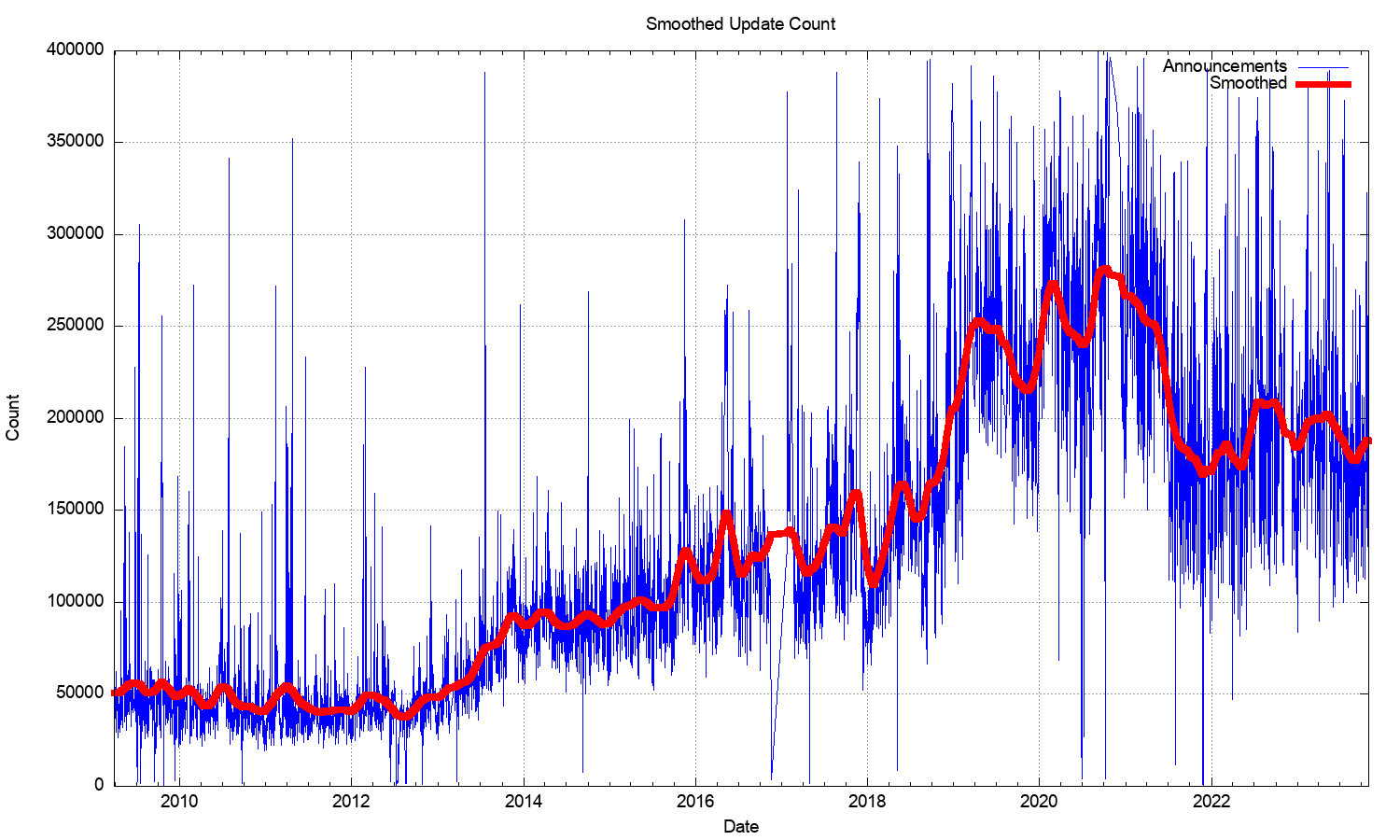{kind=link}
However, there seems to be another problem: latency spikes following a roaming event.

I have no idea how someone could attribute latency spikes equivalent to ping times between Boston and Chicago to a MAC move event. Unless there’s some magic going on behind the scenes:
- The end-user NIC disappears from point A, and the switch is unaware of that (not likely with WiFi).
- The rest of the network remains clueless; traffic to the NIC MAC address is still sent to the original switch and dropped.
- The EVPN MAC move procedure starts when the end-user NIC reappears at point B.
- Once the network figures out the MAC address has moved, the traffic gets forwarded to the new attachment point.
Where’s latency in that? The only way to introduce latency in that process is to have traffic buffered at some point, but that’s not a problem you can solve with EVPN or LISP. All you can get with EVPN or LISP is the notification that the MAC address is now reachable via another egress switch.
OK, maybe the engineer writing about latency misspoke and meant the traffic is disrupted for 20 msec. In other words, the MAC move event takes 20 msec. Could LISP be better than EVPN in handling that? Of course, but it all comes down to the quality of implementation. In both cases:
- A switch control plane has to notice its hardware discovered a new MAC address (forty years after the STP was invented, we’re still doing dynamic MAC learning at the fabric edge).
- The new MAC address is announced to some central entity (route reflector), which propagates the update to all other edge devices.
- The edge devices install the new MAC-to-next-hop mapping into the forwarding tables.
Barring implementation differences, there’s no fundamental reason why one control-plane protocol would do the above process better than another one.
But wait, there’s another gotcha: at least in some implementations, the control plane takes “forever” to notice a new MAC address. However, that’s a hardware-related quirk, and no control-plane protocol will fix that one. No wonder some people talk about dynamic MAC learning with EVPN.
Aside: If you care about fast MAC mobility, you might be better off doing dynamic MAC learning across the fabric. You don’t need EVPN or LISP to do that; VXLAN fabric with ingress replication or SPB will work just fine.
Before doing a summary, let me throw in a few more numbers:
- We don’t know how fast modern switches can update their ASIC tables (thank you, ASIC vendors), but the rumors talk about 1000+ entries per second.
- The behavior of open-source routing daemons and even commercial BGP stacks is well-documented thanks to the excellent work by Justin Pietch. Unfortunately, he didn’t publish the raw data, but looking at his graphs, it seems that good open-source daemons have no problems processing 10K prefixes in a second or two.
It seems like we’re at a point where (assuming optimal implementations) the BGP update processing rate on a decent CPU1 exceeds the FIB installation rate.
Back to LISP versus EVPN. It should be evident by now that:
- A campus network is probably not more dynamic than the global Internet;
- BGP handles the churn in the global Internet just fine, and there’s no technological reason why it couldn’t do the same in an EVPN-based campus.
- BGP implementations can handle at least as many updates as can be installed in the hardware FIB.
- Regardless of the actual numbers, decent control-plane implementations and modern ASICs are fast enough to deal with highly dynamic environments.
- Implementing control-plane-based MAC mobility with a minimum traffic loss interval is a complex undertaking that depends on more than just a control-plane protocol.
There might be a reason only a single business unit of a single vendor uses LISP in their fabric solution (hint: regardless of what the whitepapers say, it has little to do with technology).
-
Bonus points for using multiple threads on a multi-core CPU. ↩︎
>>There might be a reason only a single business unit of a single vendor uses LISP in their fabric solution >>(hint: regardless of what the whitepapers say, it has little to do with technology).
... and even that vendor realized that it's time to move on and are now officially supporting EVPN for their fabric (and is praising themselves for the wonderful interoperability options they get with EVPN, see f.e. BRKENS-2092 & BRKENS-2050 from CL Amsterdam 2024). So if you ask me: LISP was & is terminal, now on life-support, will be dead soon...
Will be interesting to see how the migration path for existing deployments will look like, if there will be one...
I will leave it to others to debate the nuances of LISP vs. EVPN... I've been in management too long at this point. But I can tell you that our support for EVPN does not, in any way, indicate the retirement of LISP for SD-Access. We have some customers (readers of Ivan's blog?) who do not want to do LISP for whatever reason, and so we support EVPN. If that's how you want to do it, that's fine. If it helps, think of it as an EIGRP vs. OSPF vs. ISIS sort of thing. Do what's best for you and we'll support it.
Nice to hear the Cisco intends to support LISP. However, it is removed from IOS XR already. So it is not that clear...
If Cisco will stop supporting LISP, then we will be forced to create our own LISP routers, since we need it for extreme mobility environments.
It would be still beneficial to have a second LISP router supplier. Unfortunately, the early LISP implementers stopped all development many years ago, so they are useless as alternative suppliers, since PUBSUB is not provided and some other features are also missing. ONOS and ODL implementations are also orphaned and useless.
In safety critical networks, we always need diversity in suppliers, too. However, now we are forced to work on technology diversity, so we have to find a way to make PMIPv6 to work reasonably well. It will be a challenging task...
We will have to present a combined mobility network with parallel LISP and PMIPv6 mobility backbones, where the end user would not see any functional limitations in multi-link mobility.
Hi Ivan thanks for nice article on the topic. At https://ibb.co/6JDr03D there is graph of all lisp fabric roaming delays attached. Number of roaming users is not easily calculable (DNAC has no such feature yet :0). Population of wireless endpoints is ~2.1K
Thanks a million. I'm assuming the "roaming distribution" (Y axis) is the number of roaming events... if only we'd know what the time unit is ;)
it's time in ms taken by host to roam. not delay actually.
pardon. my bad. Y looks like relation of the times of registered roamings counting to all number of active mobile endpoints. will ask CTAC :0)
There is one critical point. You assume anchored mobility for option one. This is unacceptable for safety critical networks. You should have mobility without an anchor point. Exactly that is what LISP provides for you. A fully distributed data plane without any single point of failure. The control plane is centralized logically, but could be fully distributed, even geo-redundant physically. You might say that single point of failures are not an issue in most networks. But in other networks this might be not acceptable.
For option two, with BGP you cannot reach the same speed of mobility and scale, because of the complex BGP path selection algorithm. On the same CPU LISP will be always much faster. Cisco once did an in-house race on this issue. LISP was the clear winner against the best BGP experts available inside Cisco. BTW, Boeing Connexion failed miserably many years ago with BGP based mobility.
If mobility is not an issue, you might be happy with option one, then EVPN might be good enough. If you need distributed anchorless mobility, than LISP will be always better by architecture.
LISP is especially a good fit for parallel active multilink mobility using Priority and Weight. PMIPv6 cannot do the same. BGP also does not have anything standardized for such scenarios. Few networks would need that today, but probably in the future all moving vehicles will have higher safety and security requirements. Then LISP is an easy natural solution. While all other protocols has to be redefined and implemented new. Even 3GPP does not have a comparable mobility solution yet.
I know you work in environments that are very far away (requirements-wise) from "typical" networks, so it's always great to have your perspective. Thanks a million!
As for the "complex BGP path selection algorithm," that's definitely true, but in a typical (sane) EVPN scenario, all path attributes should match, and thus, the actual code path should be relatively simple.
I am positive nobody ever optimized BGP for the speed of simple path selection, but then we also didn't have JavaScript JIT compilers until people started running JS on the servers. This discussion somewhat reminds me of the famous IS-IS versus OSPF wars, where it turned out that one of the main reasons for sub-par OSPF performance on Cisco IOS (so the rumors go) was that the team writing the IS-IS code was better (because they had to deal with larger customers).
Anyway, it turns out that we usually "solve" problems with brute-force application of more resources, and as long as the ASIC FIB programming remains the bottleneck, it doesn't matter (in the data center/campus switching space) too much how much faster LISP is... or am I missing something?
without SDA-transit (PUB/SUB) in the WAN mobility w/ LISP ends on the arbitrary Fabric Site.
FIB update speed is very much different on the specific router architecture. How does it compare to running BGP path selection for a large number of mobility events? Difficult to say in general. Depends on a lot of internal parameters how to share computing resources.
In some newer routers BGP would not be such a big bottleneck, but you need a lot of knob turning in BGP to get it right, while in LISP it is quite simple.
If you have many thousands concurrent airplanes with multi-link and max. 16 subnets with different routing policies on each, and the radio links are going up and down, then you have a large number of mobility events.
This is where LISP with PUBSUB is excellent. BGP is not designed for mobility and in such an extreme environment would be a serious bottleneck, potentially making impossible to fulfill the safety performance requirements.
Victor Moreno published once an exercise with moving robots in factory environment where similar mobility performance was required. LISP was the right fit for that.
It is a totally different use case of LISP than most people would think about. Valid only with PUBSUB. Still some points are missing to make this solution complete. Reliable transport shall be standardized. We need subnetwork mobility support in MS/MR. Some LCAF extension and implementation would be handy.
However, I see no good alternative. PMIPv6 is a candidate, but it has no support for full multilink with policies yet. For me LISP is the best mobility protocol, a replacement for PMIPv6, not a replacement for BGP. Actually, in the RLOC space underlay you would typically have a telco network with a lot of BGP.
LISP is also useful for replacing private WAN overlay MPLS networks. It is much simpler to learn and maintain. It could be easily secured by GETVPN with group keys.
i dont clearly get your references to "policies with LISP". VXLAN is able to carry on group policy tags (along with VNIDs) w/o LISP. Another one (& not last) concern with LISP PUBSUB is it requires RLOCs /32 to populate underlay routing proto's RIBs. I wonder how is it going to scale beyond the campus?
Great Post! I did indeed use "Latency" as twitter shorthand/laziness instead of your more elegant description above.
At the time of the tweet I was arguing for VxLAN EVPN with some of my peers but I had no direct hands on knowledge of how it would actually perform and very limited ability to lab it on hardware. My client was considering deploying Campus VxLAN and they have one of the largest campuses in North America.
Since the tweet I have learned an additional data point. Arista helped them test roaming on Campus EVPN. Here is the description from my contact at Arista.
Roaming and MAC moves across an EVPN/VxLAN environment was a concern to XXXX and we had our PM & SysTest teams help address their concerns back in Oct 2022.
They simulated 60k clients across 2500 APs and MAC moves at various frequencies; XXXX's client scale is closer to 30k for the Home Office.
Here are the highlights of our PM team's recommendations.
WiFi Data Path • The recommendation is Vxlan tunnel mode back to a pair of dedicated aggregation switches so the MAC moves are not updating across the fabric. WiFi VLAN • Single or Multiple VLAN does not matter, as all the client traffic is tunneled to the aggregation switch pair. Wired Design • Choice of L2 or L3 at access leaf does not matter for WiFi clients as the MAC visibility is on the aggregation switch pair. Roaming • Seamless roaming across the entire campus with no impact to any apps.
DHCP Broadcast/ mDNS • DHCP broadcast will be flooded on the wired side from the aggregation switch pair. Need DHCP broadcast to unicast conversion.